権威のあるDP-600勉強方法一回合格-一番優秀なDP-600受験対策解説集
Wiki Article
P.S.CertJukenがGoogle Driveで共有している無料の2026 Microsoft DP-600ダンプ:https://drive.google.com/open?id=1Xr5iNnJ8LHmts9Wv50hpPzcXMiHQnlAg
DP-600ガイド資料の誤った情報を取得する心配はありません。個人の好みと予算の選択に応じて、ショッピングカートに参加するための適切な商品を選択します。 DP-600学習資料の3つの形式は、PDF、ソフトウェア/ PC、およびAPP /オンラインです。各形式には、明確な長所と短所があります。専門家によって作成された印刷可能なPDF形式があり、ダウンロードにアクセスできれば、いつでもどこでもDP-600トレーニングエンジンを学習できます。また、DP-600シミュレートされた実際の試験環境を備えたインストール可能なソフトウェアアプリケーションもあります。
Microsoft DP-600 認定試験の出題範囲:
| トピック | 出題範囲 |
|---|---|
| トピック 1 |
|
| トピック 2 |
|
| トピック 3 |
|
DP-600受験対策解説集、DP-600問題トレーリング
試験を受けることでMicrosoft認定を取得することを期待する人が増えています。ただし、多くの人にとって試験は非常に困難です。特に正しい学習教材を選択せずに適切な方法を見つけた場合、DP-600試験に合格して関連する認定を取得することはより困難になります。関連する認定を効率的な方法で取得したい場合は、当社のDP-600学習教材を選択してください。弊社のDP-600学習教材が試験に合格し、簡単に認定を取得するのに役立ちます。
Microsoft Implementing Analytics Solutions Using Microsoft Fabric 認定 DP-600 試験問題 (Q142-Q147):
質問 # 142
You have a Fabric warehouse that contains a table named Staging.Sales. Staging.Sales contains the following columns.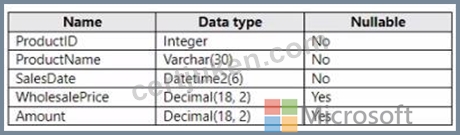
You need to write a T-SQL query that will return data for the year 2023 that displays ProductID and ProductName arxl has a summarized Amount that is higher than 10,000. Which query should you use?
- A.

- B.
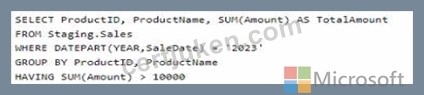
- C.

- D.

正解:C
解説:
The correct query to use in order to return data for the year 2023 that displays ProductID, ProductName, and has a summarized Amount greater than 10,000 is Option B. The reason is that it uses the GROUP BY clause to organize the data by ProductID and ProductName and then filters the result using the HAVING clause to only include groups where the sum of Amount is greater than 10,000. Additionally, the DATEPART(YEAR, SaleDate) = '2023' part of the HAVING clause ensures that only records from the year 2023 are included.
References = For more information, please visit the official documentation on T-SQL queries and the GROUP BY clause at T-SQL GROUP BY.
質問 # 143
You have a Fabric tenant that contains a lakehouse named Lakehouse1. You have forecast data stored in Azure Data Lake Storage Gen2. You plan to ingest the forecast data into Lakehouse1.
The data is already formatted, and you do NOT need to apply any further data transformations.
The solution must minimize development effort and costs.
Which method should you recommend to efficiently ingest the data?
- A. Use Dataflow Gen2.
- B. First, download the data to your computer, and then use Lakehouse explorer to upload it to Lakehouse1.
- C. Use the Copy activity in a pipeline.
- D. Use a Spark notebook.
正解:C
質問 # 144
Case Study 1 - Contoso
Overview
Contoso, Ltd. is a US-based health supplements company. Contoso has two divisions named Sales and Research. The Sales division contains two departments named Online Sales and Retail Sales. The Research division assigns internally developed product lines to individual teams of researchers and analysts.
Existing Environment
Identity Environment
Contoso has a Microsoft Entra tenant named contoso.com. The tenant contains two groups named ResearchReviewersGroup1 and ResearchReviewersGroup2.
Data Environment
Contoso has the following data environment:
- The Sales division uses a Microsoft Power BI Premium capacity.
- The semantic model of the Online Sales department includes a fact table named Orders that uses Import made. In the system of origin, the OrderID value represents the sequence in which orders are created.
- The Research department uses an on-premises, third-party data warehousing product.
- Fabric is enabled for contoso.com.
- An Azure Data Lake Storage Gen2 storage account named storage1 contains Research division data for a product line named Productline1. - The data is in the delta format.
- A Data Lake Storage Gen2 storage account named storage2 contains Research division data for a product line named Productline2. The data is in the CSV format.
Requirements
Planned Changes
Contoso plans to make the following changes:
- Enable support for Fabric in the Power BI Premium capacity used by the Sales division.
- Make all the data for the Sales division and the Research division available in Fabric.
- For the Research division, create two Fabric workspaces named Productline1ws and Productine2ws.
- In Productline1ws, create a lakehouse named Lakehouse1.
- In Lakehouse1, create a shortcut to storage1 named ResearchProduct.
Data Analytics Requirements
Contoso identifies the following data analytics requirements:
- All the workspaces for the Sales division and the Research division must support all Fabric experiences.
- The Research division workspaces must use a dedicated, on-demand capacity that has per- minute billing.
- The Research division workspaces must be grouped together logically to support OneLake data hub filtering based on the department name.
- For the Research division workspaces, the members of ResearchReviewersGroup1 must be able to read lakehouse and warehouse data and shortcuts by using SQL endpoints.
- For the Research division workspaces, the members of ResearchReviewersGroup2 must be able to read lakehouse data by using Lakehouse explorer.
- All the semantic models and reports for the Research division must use version control that supports branching.
Data Preparation Requirements
Contoso identifies the following data preparation requirements:
- The Research division data for Productline1 must be retrieved from Lakehouse1 by using Fabric notebooks.
- All the Research division data in the lakehouses must be presented as managed tables in Lakehouse explorer.
Semantic Model Requirements
Contoso identifies the following requirements for implementing and managing semantic models:
- The number of rows added to the Orders table during refreshes must be minimized.
- The semantic models in the Research division workspaces must use Direct Lake mode.
General Requirements
Contoso identifies the following high-level requirements that must be considered for all solutions:
- Follow the principle of least privilege when applicable.
- Minimize implementation and maintenance effort when possible.
Hotspot Question
Which workspace role assignments should you recommend for ResearchReviewersGroup1 and ResearchReviewersGroup2? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.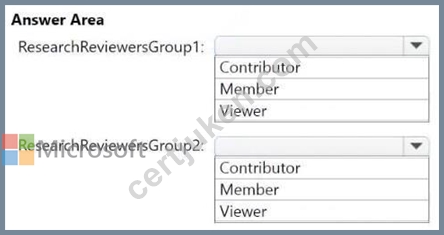
正解:
解説: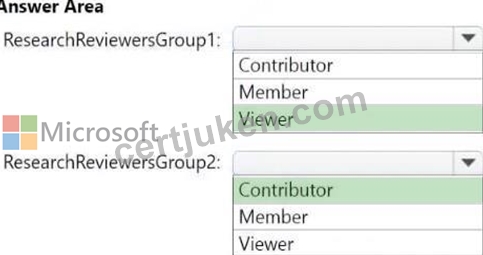
Explanation:
https://learn.microsoft.com/en-us/fabric/get-started/roles-workspaces
質問 # 145
You have a semantic model named Model 1. Model 1 contains five tables that all use Import mode. Model1 contains a dynamic row-level security (RLS) role named HR. The HR role filters employee data so that HR managers only see the data of the department to which they are assigned.
You publish Model1 to a Fabric tenant and configure RLS role membership. You share the model and related reports to users.
An HR manager reports that the data they see in a report is incomplete.
What should you do to validate the data seen by the HR Manager?
- A. Select Test as role to view the data as the HR role.
- B. Ask the HR manager to open the report in Microsoft Power Bl Desktop.
- C. Filter the data in the report to match the intended logic of the filter for the HR department.
- D. Select Test as role to view the report as the HR manager,
正解:A
解説:
To validate the data seen by the HR manager, you should use the 'Test as role' feature in Power BI service.
This allows you to see the data exactly as it would appear for the HR role, considering the dynamic RLS setup.
Here is how you would proceed:
* Navigate to the Power BI service and locate Model1.
* Access the dataset settings for Model1.
* Find the security/RLS settings where you configured the roles.
* Use the 'Test as role' feature to simulate the report viewing experience as the HR role.
* Review the data and the filters applied to ensure that the RLS is functioning correctly.
* If discrepancies are found, adjust the RLS expressions or the role membership as needed.
References: The 'Test as role' feature and its use for validating RLS in Power BI is covered in the Power BI documentation available on Microsoft's official documentation.
質問 # 146
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric tenant that contains a semantic model named Model1.
You discover that the following query performs slowly against Model1.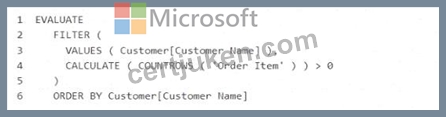
You need to reduce the execution time of the query.
Solution: You replace line 4 by using the following code:
Does this meet the goal?
- A. No
- B. Yes
正解:A
質問 # 147
......
MicrosoftのDP-600試験に参加するのは大ブレークになる一方が、DP-600試験情報は雑多などの問題が注目している。たくさんの品質高く問題集を取り除き、我々CertJukenのDP-600問題集を選らんでくださいませんか。我々のDP-600問題集はあなたに質高いかつ完備の情報を提供し、成功へ近道のショットカットになります。
DP-600受験対策解説集: https://www.certjuken.com/DP-600-exam.html
- DP-600問題集無料 ???? DP-600試験問題 ???? DP-600試験問題 ???? 【 www.xhs1991.com 】の無料ダウンロード[ DP-600 ]ページが開きますDP-600模擬体験
- DP-600試験の準備方法|更新するDP-600勉強方法試験|ユニークなImplementing Analytics Solutions Using Microsoft Fabric受験対策解説集 ???? ➥ www.goshiken.com ????サイトにて最新➥ DP-600 ????問題集をダウンロードDP-600問題集
- DP-600日本語試験対策 ???? DP-600参考書 ???? DP-600前提条件 ???? ▷ www.mogiexam.com ◁の無料ダウンロード[ DP-600 ]ページが開きますDP-600認定デベロッパー
- 権威のあるDP-600勉強方法 - 合格スムーズDP-600受験対策解説集 | 高品質なDP-600問題トレーリング ???? ⇛ www.goshiken.com ⇚を開いて✔ DP-600 ️✔️を検索し、試験資料を無料でダウンロードしてくださいDP-600資格復習テキスト
- 権威のあるDP-600勉強方法 - 合格スムーズDP-600受験対策解説集 | 高品質なDP-600問題トレーリング ☔ 今すぐ⇛ www.mogiexam.com ⇚を開き、{ DP-600 }を検索して無料でダウンロードしてくださいDP-600日本語試験対策
- 権威のあるDP-600勉強方法 - 資格試験のリーダープロバイダー - 現実的なDP-600受験対策解説集 ???? 今すぐ[ www.goshiken.com ]で➠ DP-600 ????を検索して、無料でダウンロードしてくださいDP-600問題集無料
- DP-600復習時間 ↩ DP-600認定デベロッパー ‼ DP-600復習資料 ???? URL ⮆ www.jpshiken.com ⮄をコピーして開き、《 DP-600 》を検索して無料でダウンロードしてくださいDP-600資格取得
- DP-600認定デベロッパー ???? DP-600一発合格 ???? DP-600一発合格 ???? ➽ DP-600 ????を無料でダウンロード▷ www.goshiken.com ◁で検索するだけDP-600認定デベロッパー
- DP-600的中率 ???? DP-600前提条件 ???? DP-600復習テキスト ⚾ ⇛ jp.fast2test.com ⇚を開き、“ DP-600 ”を入力して、無料でダウンロードしてくださいDP-600科目対策
- 試験の準備方法-信頼的なDP-600勉強方法試験-認定するDP-600受験対策解説集 ❕ 今すぐ➠ www.goshiken.com ????で➡ DP-600 ️⬅️を検索し、無料でダウンロードしてくださいDP-600参考書
- 権威のあるDP-600勉強方法 - 合格スムーズDP-600受験対策解説集 | 高品質なDP-600問題トレーリング ???? ▛ www.xhs1991.com ▟は、{ DP-600 }を無料でダウンロードするのに最適なサイトですDP-600参考書
- harleyesoy612908.livebloggs.com, www.stes.tyc.edu.tw, funbookmarking.com, www.stes.tyc.edu.tw, anniejyab615729.qodsblog.com, highkeysocial.com, www.stes.tyc.edu.tw, socialwebconsult.com, ezekielkcwm260806.wikiinside.com, tayameis417467.blogsidea.com, Disposable vapes
さらに、CertJuken DP-600ダンプの一部が現在無料で提供されています:https://drive.google.com/open?id=1Xr5iNnJ8LHmts9Wv50hpPzcXMiHQnlAg
Report this wiki page